A robots.txt generator is a tool used for creating a robots.txt file for a website. The robots.txt file is a plain text file placed in the root directory of a website, and it provides instructions to web crawlers or robots on which parts of the site they can or cannot access.
Robots.txt is a vital component of any website’s SEO strategy.
Properly implemented robots.txt can help you to control access to sensitive areas, conserve server resources, and prioritize valuable content for indexing. However, incorrect usage can lead to unintended consequences and negatively impact website visibility and ranking.
Also read: Google Indexing and How Web Crawler Works
What is Robots. txt?
Robots.txt is a text file placed on a website’s root directory, which provides instructions to web crawlers (also known as web bots or spider) about which parts of the site they can or cannot access. This file acts as a roadmap for search engine spiders, indicating which pages should be crawled and indexed and which ones should not.
Importance of Robots. txt
Below are some importance of robots.txt:
- Robots.txt allows webmasters or developers to control how search engines navigate their websites. By specifying the directories or pages that should be excluded from indexing, you can prevent search engines from crawling sensitive information or low-value pages.
- Search engine crawlers consume server resources while indexing a website. By using robots.txt to limit crawlers’ access to non-essential areas, you can conserve server bandwidth and reduce the load on their servers.
- You can use robots.txt to prioritize important pages or directories, directing search engines to focus on indexing those that contribute the most to the website’s overall value.
- By disallowing crawlers from accessing certain directories, you can enhance the privacy and security of sensitive data, such as admin panels or user accounts.
Suggested read: RoadMap to Becoming An SEO Expert
Also read: 13 Key Indications that your SEO Strategy is Successful
Implications of Using Robots.txt Incorrectly
While robots.txt offers numerous benefits, using it incorrectly can have unintended consequences, negatively impacting website indexing and search rankings. Common mistakes include:
- Blocking Essential Pages: Misconfiguration may result in search engines being blocked from indexing crucial pages, causing a drop in organic traffic and visibility.
- Unintentional Disallowance: A single typo or syntax error in the robots.txt file can inadvertently block crawlers from indexing an entire website.
- Mixed Signals: Inconsistent or conflicting instructions in robots.txt and meta tags can confuse search engines, leading to incomplete indexing and unpredictable rankings.
- Indexing Duplicate Content: If not properly managed, robots.txt can allow search engines to index duplicate content, which can adversely affect SEO efforts.
- Blocking CSS and JavaScript Files: Preventing search engines from accessing CSS and JavaScript files can lead to improper website rendering, resulting in a poor user experience.
So, it is important that you carefully review and test your robots.txt file before implementation.
Suggested read: 6 Ultimate Dangers of Using Free Public WiFi
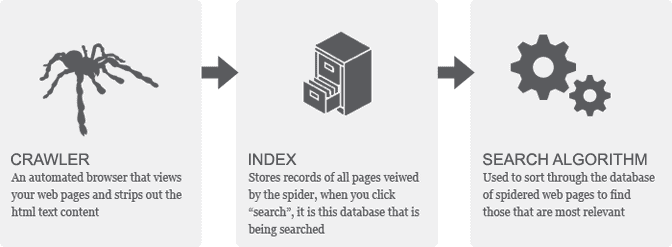
How Does Google Find and Index Web Pages?
Google uses a process called “crawling” to find and index web pages and it is done in following order;
- Crawling: Google uses automated programs called “Googlebot” or “spiders” to crawl the web. These bots follow links from one page to another, and as they go, they collect information about each page they visit, including its content, structure, and any links it contains.
- Indexing: Once Googlebot has crawled a web page, the information it collects is added to Google’s index. This is essentially a massive database of all the pages that Google has crawled, organized by keywords and other relevant data.
- Ranking: When someone performs a search on Google, the search engine uses an algorithm to determine which pages in its index are most relevant to the query. This algorithm takes into account a wide range of factors, including the content of the page, the quality and relevance of the links pointing to it, and the user’s location and search history.
Also read: Differences And Benefits of Short and Long Tail Keywords in SEO
How Does Google Use Robots. t x t?
When Googlebot (Google’s web crawler) encounters a robots.txt file on a site, it reads and interprets the instructions contained within. These instructions guide Googlebot on which pages to crawl, which directories to avoid, and how often to revisit the site.
Also: WordPress Theme Detector – How to Detect WordPress Websites
How to Check a Robots.txt File on a Website
To verify a website’s robots.txt file, follow these steps:
- You can manually check by typing the website’s URL followed by “/robots.txt” (e.g., www.example.com/robots.txt) into your web browser. This will display the robots.txt file, if available. If your website doesn’t have one, then you should generate it by using Robots txt generator.
- Alternatively, you can check if your website has a robots.txt file using Google Search Cole. Google search console has a “robots.txt Tester” tool that provides valuable insights into how Googlebot interacts with the file.
How to Generate a Robots.t x t
You can generate a robots.txt file for your website by following the steps below:
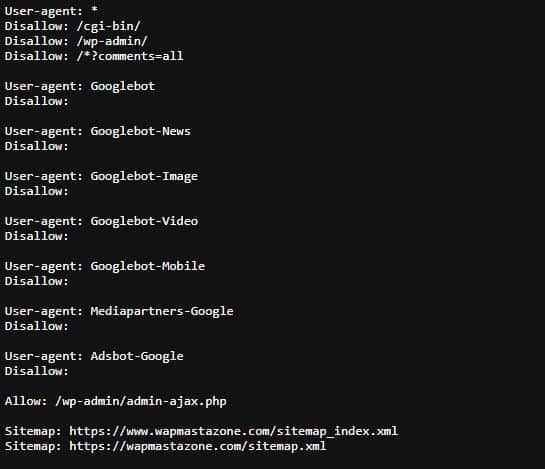
- But before you generate the robot.txt file, ensure to determine which directories should be excluded from indexing. Common directories to block include admin panels, login pages, and any sections containing sensitive or confidential data. For instance, the image below shows our website’s robots.txt and what we have allowed and disallowed.
2. You can use any of the 3 generators below
- Robots txt generator 1 – https://seotools.wapmastazone.com/robots-txt-generator
- Robots txt generator 2 – https://seooptimizer.me/robots-txt-generator
- Robots txt generator 3 – https://www.my-seotools.com/robots-txt-generator
3. Once you generate the txt file, ensure to test it before deploying the robots.txt file to the live site, test it using the “robots.txt Tester” tool in Google Search Console to check for errors or unintended exclusions.
4. Finally, you can update when necessary.
Also read: 40 SEO Faqs (SEO Frequently Asked Questions)
Also read: What is SEO Optimizer
Suggested read: SEO Education – 7 Reasons Why SEO Isn’t Taught in College



